API Function Hashing in a Cobalt Strike Shellcode Loaders
Malware authors frequently employ API hashing to obfuscate their use of system APIs and evade static detection. Rather than storing readable API names, malware samples store precomputed hash values. At runtime, these hashes are compared against the hashes of exported function names retrieved dynamically from loaded DLLs. If a match is found, the corresponding function pointer is resolved and used in later execution stages.
This post documents how a Cobalt Strike shellcode loader implements API function hashing, focusing on how it parses a hardcoded data block, performs hashing, and dynamically resolves function addresses.
Data Block Allocation and Preparation
During execution, the loader allocates a heap (v3) and copies a block of hardcoded data into it. This memory region is then passed as the first argument to a function renamed resolve_ptrs.

Block of data as it appears in IDA.

This heap data is then copied to a specific memory address, qword_7FFA43FE5168, and passed as the second argument to a function renamed hash_function. The first argument to hash_function is either:
- The name of the loaded DLL (retrieved from the process’s PE structure), or
- The name of an exported function from that DLL.
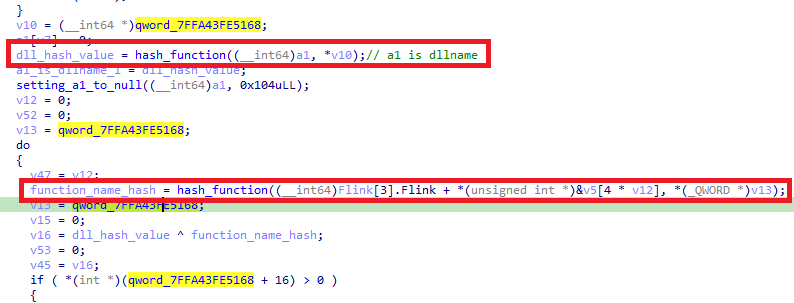
The data in the preset memory location can be verified in a debugger.
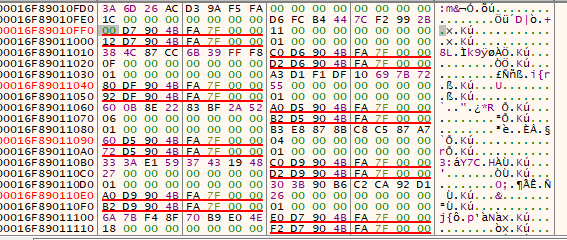
API Hashing Logic
The hash_function uses qword_7FFA43FE5168 as a constant seed. This value corresponds to the first 8 bytes of the data block: 0xFAF59AD3AC266D3C.

Summary of Observations
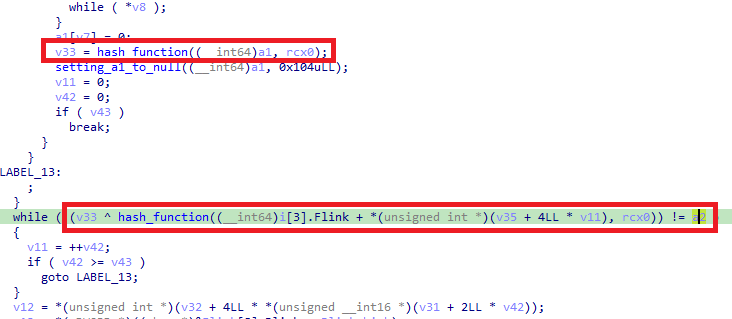
- The hash of the DLL name is XOR’ed with the hash of the function name, and the result is saved in
v16. v17serves as the offset into the data block.- The resulting value
v16is compared against a value at offset 24 in the data block.
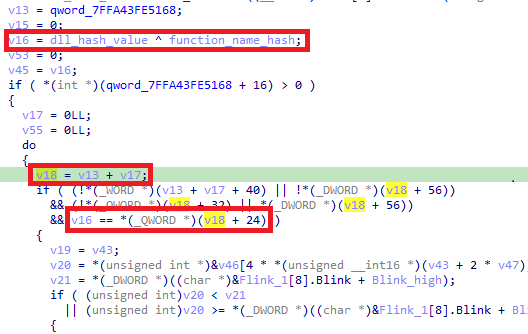
Offset 24 contains another 8-byte value: 0x2B99F27C44B4FCD6. This value is the XOR of a hashed function name and its corresponding DLL hash, implying that a match indicates a valid function resolution.
The loop increments v17 by 40 bytes each iteration, checking values at increasing offsets. The loop continues while the counter v15 remains below the byte at offset 16, which is 0x1c (28 in decimal), indicating the number of entries.
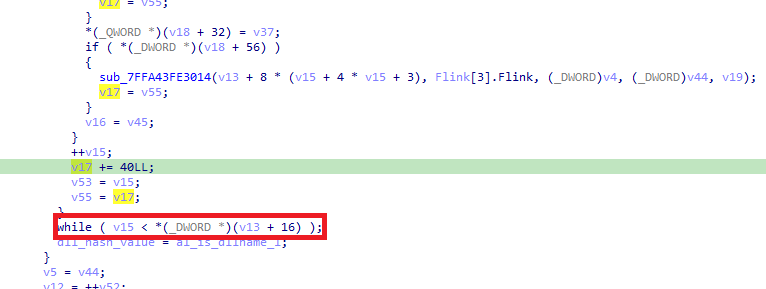
At offset 40, we see the value 0xF8FF396BCC874C38.
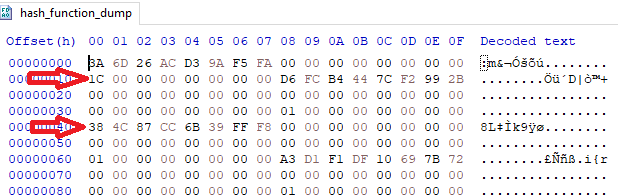
Drom these observations, we can infer the data block structure:
- Offset 0 (8 bytes): Constant seed for the hash function
- Offset 16 (1 byte): Number of function hashes to resolve (
0x1c) - Offset 24 onward (40-byte entries): Each entry holds an obfuscated hash value representing hash(func) XOR hash(dll)
Function Pointer Resolution
Following the main do-while loop, a for loop scans the data block in 40-byte increments starting at offset 32. This phase attempts to resolve the actual function pointers.
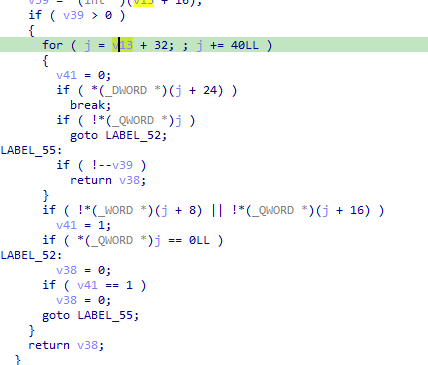
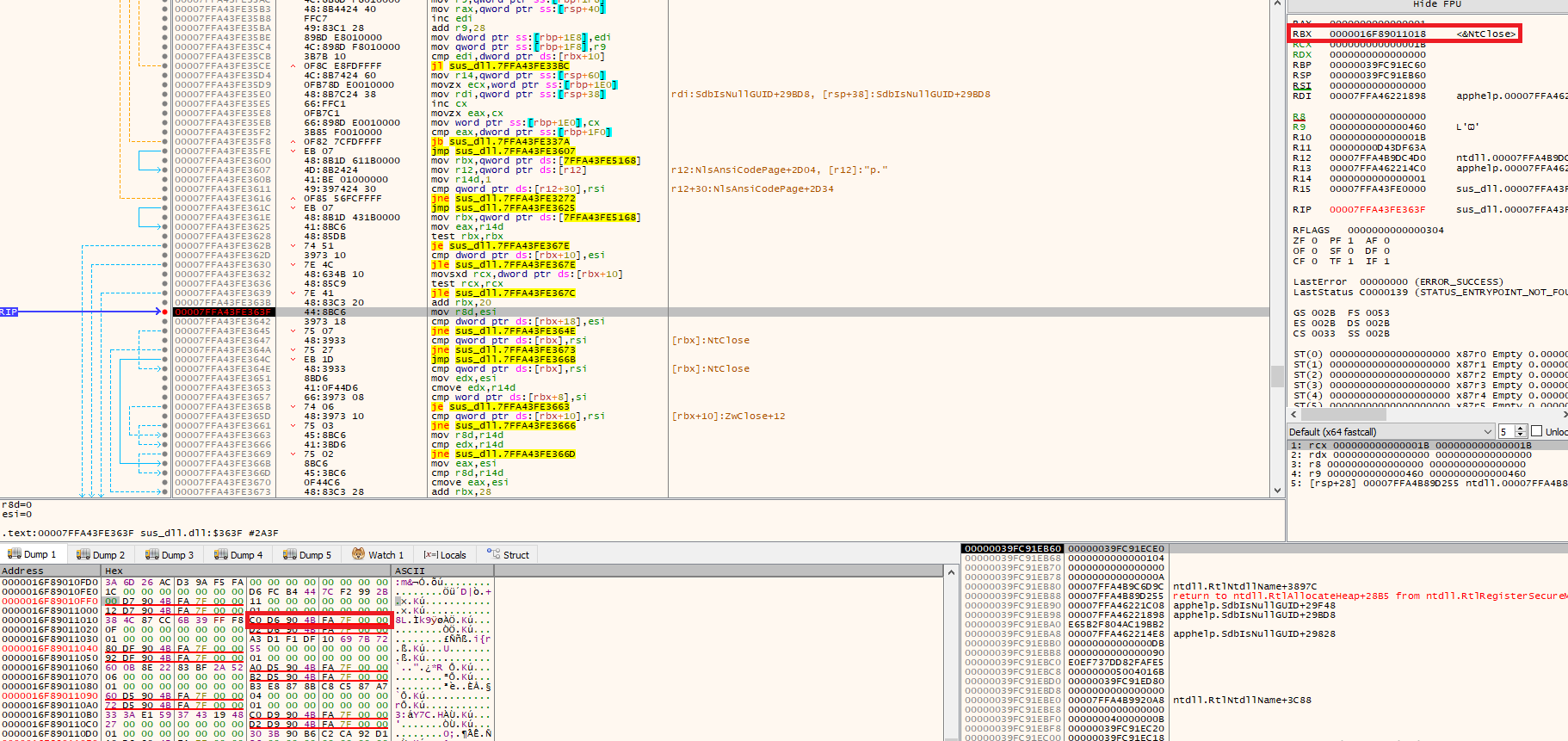
When run in a debugger, we observe that these offsets eventually hold valid function addresses:
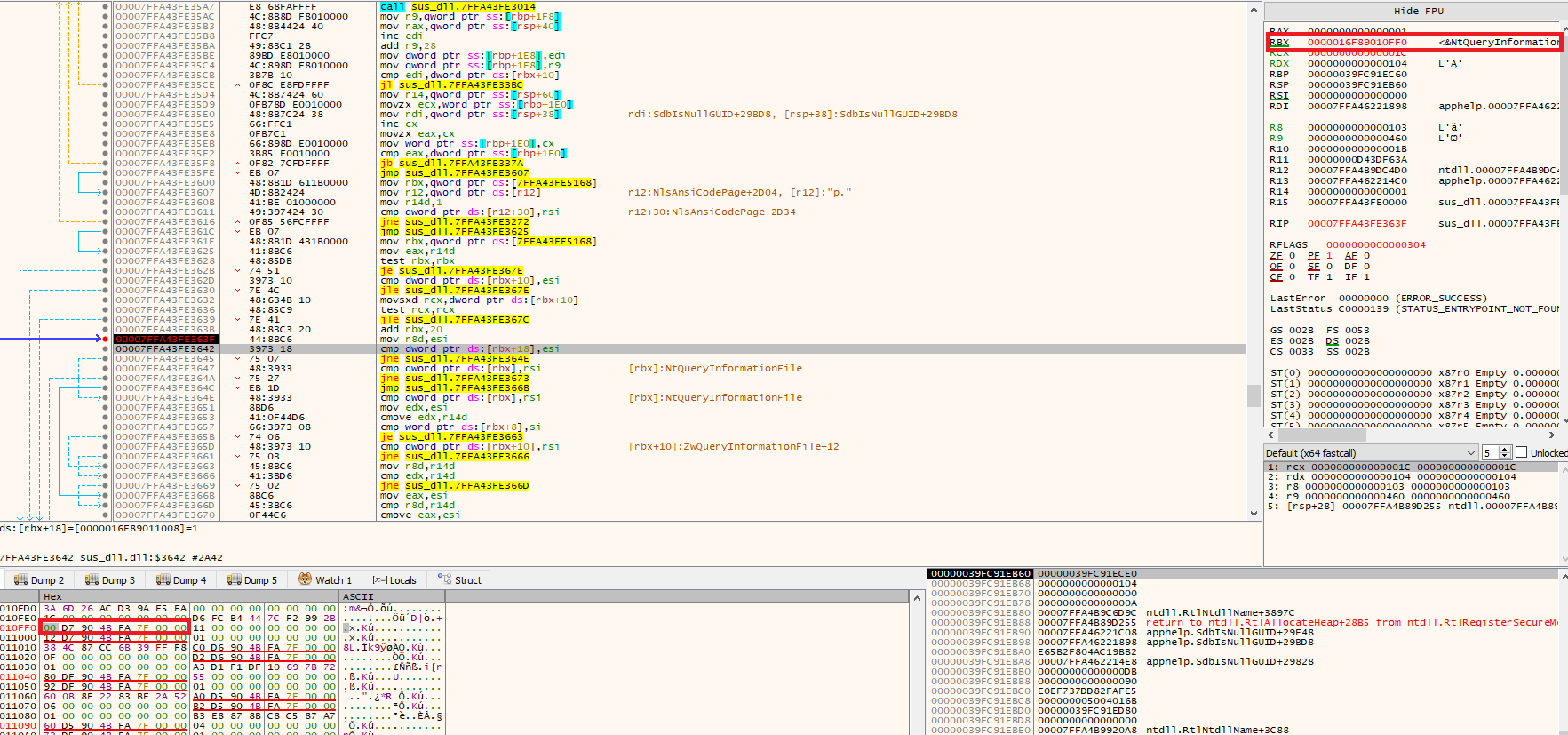
State of the registers in the next loop.
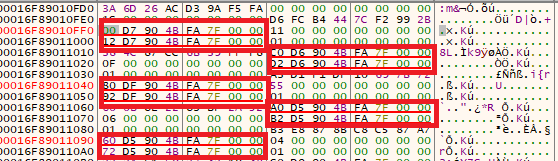
The first pointer often targets the entry point of a function, while the second may point to an offset within that function—potentially used for indirect syscall stubs. This was only observed for the first few number of function pointers.
Alternative Hash Constants
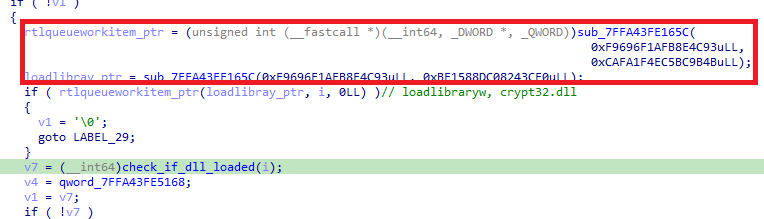
Interestingly, not all function hashes use the initial 8-byte constant from the data block. In some cases, the constant is hardcoded inline within the function.
For example, the value 0xF9696F1AFB8E4C93 is used directly:
However, the logic remains consistent: the hash of the DLL name and function name are XOR’ed to match the obfuscated value in the data block.
Conclusion
API hashing remains a widely used evasion technique in malware, especially in advanced tooling like Cobalt Strike. By leveraging XORed hash values and indirect resolution via memory-resident data blocks, these loaders can dynamically resolve only the APIs they need, without revealing names in cleartext.
Understanding this technique and its implementation patterns is crucial for analysts when reverse-engineering obfuscated loaders, detecting shellcode behavior, and building effective detection strategies.